


💆 Some Unsatisfying Solutions for Facebook
In the limitations of each of these solutions, we can find lessons for a healthier information ecosystem

Oh, hello. Welcome to the second monthly series of Untangled. Last month I wrote about how Crypto isn't decentralized, interviewed law professor Angela Walch about the idea of treating software developers as fiduciaries, and then chatted with Nathan Schneider on crypto governance.
👉 If someone forwarded this email to you, you're in for a treat. But you will get SEVERAL treats if you subscribe.
This month, I've decided to give you a series of unsatisfying solutions for a big fat problem: Facebook. Yes, yes... I can hear you laugh-crying already.
Solution 0: rename the company, "Meta." The end.
That's the kind of incisive analysis you'll get with Untangled!
I'm kidding, of course. But I'm not kidding about this: we're trapped in a transparency feedback loop.

With Facebook, the feedback loop looks something like this: there are information leaks and demands for transparency, and these reveal problems we didn't know of before, which prompts calls for more transparency, which identifies still more problems. And on, and on, we go.
This issue of Untangled applies a framework for transparency and accountability to three oft highlighted proposals, and explores the limitations of each:
Freeing the data
Auditing the algorithms
Regulating reach, not speech
Ultimately what I want to do here is go beyond Facebook's failings, and ask: what does a healthy information ecosystem look like?
Solution 1: Free the data!
⛔️ Old Assumption: Transparency leads to accountability. Data sharing is critical to both of these objectives.
Lots of researchers and academics are asking Facebook to provide data access. Nathan Persily, a professor at Stanford Law School, has drafted a bill called the "Platform Transparency and Accountability Act". Congress could adopt this tomorrow if it wanted.
We can do a lot just by opening this data up. For instance, understanding more about the spread of misinformation or even allowing researchers to assess Facebook's performance against their own terms of service. I'm supportive of sharing data with vetted researchers in a privacy-preserving manner.
But, Persily goes further and argues that "data transparency [...] represents a condition precedent to effective regulation in all of these areas." I disagree — transparency doesn't necessarily lead to accountability and platform data doesn't actually say that much about us.
Okay but, why? To answer that, let's now look at that transparency framework I mentioned.
Transparency scholars have been making this case for a while now: transparency is a means, not an end. Transparency may be used as a mechanism to achieve a policy objective, but simply 'being transparent' is not the objective — we mustn't conflate the two things.
When researching this, I've been reading a lot of Jonathan Fox's work. He talks about how we are quick to assume that transparency is always good, or will lead to something good — like accountability. He breaks both transparency and accountability into two, like this:
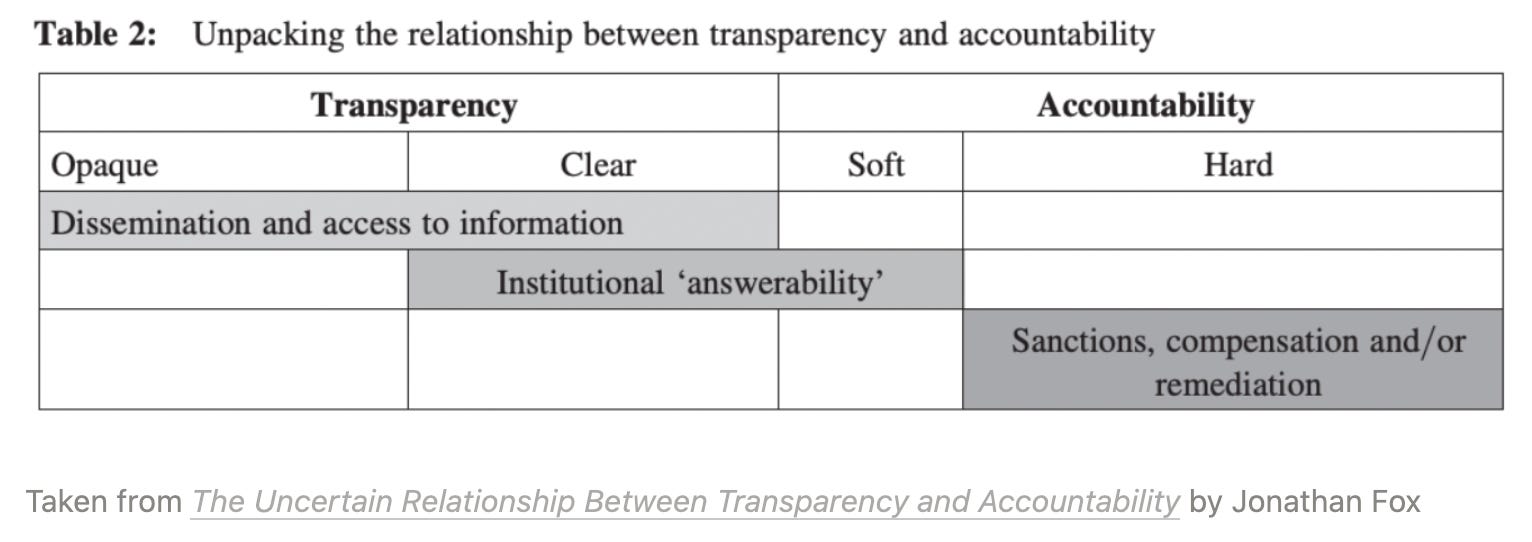
So, to expand on this:
Opaque transparency reveals information without revealing how companies actually behave. E.g. sharing data without showing what decisions and practices led to making that data.
Clear transparency reveals information in a way that "sheds light on institutional behavior" thus leading to 'institutional answerability'. Learning more about institutional behavior can also lead to...
Soft accountability, which gives us “the right to call those in authority to justify their decisions” and produce information about how they make decisions.
Hard accountability entails the ability to implement sanctions and demand remediation.
☝️ So 'freeing the data', in this framework, is a form of opaque transparency. Persily's bill would give researchers access to platform data, but reveal little about company behavior. It's a worthy start but we're still stuck in the transparency loop! Isn't it worth doing anyway, you might ask, to better understand societal problems on the platform? Yes, well, kind of.
The thing is, platform data doesn't actually tell us that much about ourselves. We once wrongly assumed that platform data was magic dust, able to see into our collective souls. But scholars like Angela Xiao Wu and Harsh Taneja now contend that platform data should be understood as "administrative data" or data that platforms use to achieve their own goals. Data are records of their probes into our behavior. They capture less about "us" and more precisely record the effects of platform nudges.
If this sounds strange or controversial to you, ask yourself this: am I a perfect reflection of myself on social media? I didn't think so.

The upshot? We can't make sense of the data without understanding how it results from the dynamic interaction between people and algorithms.
💡 New Assumption: transparency is a means, not an end. What it leads to is contingent on the circumstance. Accountability requires the ability to demand explanations and produce information or implement sanctions. Data sharing by itself doesn't move us any closer to accountability.
Solution 2: Audit the algorithms!
⛔️ Old assumption: algorithms are neutral. Math is math y'all, just open the black box and you'll learn all you need to know.
This brings us to the calls for independent audits of Facebook's algorithms. Audits are part of a family of tools used to assess algorithms. So for example, bias audits are typically conducted by researchers or journalists and assess the bias in an algorithm after it's been let loose on the world. This is a fairly new activity; back in the day, algorithms couldn't be biased. Math was just math.

How a bias audit would work in the context of Facebook: a third-party (such as researchers or journalists) would be given the code that makes up Facebook's newsfeed algorithm, so they can analyze it for problematic behavior like discrimination.
🚨 Transparency framework alert! Bias audits are just more opaque transparency:
The auditor can only reveal information about how the code itself led to a particular output.
Audits by contractors allow developers to handpick what they would like to be audited for.
Regardless, the auditor can't demand explanations about how the algorithm itself was designed, or even why.
Algorithms are entangled with the cultures of the companies that create them. It's clear from Jeff Horwitz and Will Oremus' reporting that Facebook's organizational structure, practices, and behaviors influenced the ongoing tinkering of the newsfeed algorithm. The culture at Facebook is to sideline those concerned with its negative impact and prohibit changes that are proven to limit the spread of misinformation and hate speech.
Therefore, any bias audit — or whatever audit — would have to go beyond the impacts of the algorithm itself and look at why the model was designed this way in the first place. This means looking at things such as the incentive structures within Facebook that prioritize growth over harm reduction. Or, how internal power imbalances and contradictory goals of the newsfeed and integrity teams perpetuated the spread of harmful content.
It also means interrogating the fundamental assumptions underpinning the algorithm or "the epistemological roots of the system," as AI ethics researchers Mona Sloane, Emanuel Moss, and Rumman Chowdhury put it. For example, when Facebook optimized its newsfeed for "meaningful social interactions," it assumed that more social interactions (e.g. re-shares, reactions, comments, etc.) would mean more 'meaningful interactions,' not more lies and outrage.

So while a plain old bias audit would only bring us opaque transparency, the Ada Lovelace Institute and others have proposed things like "regulatory inspections" and "algorithmic risk assessments" that could enable clear transparency for Facebook's algorithms. Or, if regulators enabled auditors to both demand explanations and produce information, we would be closer to soft accountability.
💡New assumption: algorithms are shaped by people, practices, and beliefs. To move towards accountability, algorithmic assessments should be ongoing, interrogate the decisions and assumptions that led to its design, and be able to demand changes to that design.
Solution 3: Regulate reach, not speech!
⛔️ Old assumption: Scale is good. Achieving scale means optimizing for efficiencies and removing all friction in the platform. Regulating scale means antitrust.
After everything we've seen, I think we can dispel the notion that scale is inherently good. Facebook is a case in point of what happens (re: permanent dysfunction) when you group billions of people onto the same platform.
Anytime we talk about Facebook's size, the conversation turns to antitrust. Break them up! I'm not opposed to this, though the point shouldn't be to break up the companies, but rather to break up their power. To do that, we should focus on dampening algorithmic amplification and mitigating network effects.
🔍 Network effects refer to the idea that a platform or product becomes more valuable as more people use it. Network effects create a positive feedback loop such that the platform continues to grow, allowing the company to achieve a dominant market position before a competitor can catch up.
Frances Haugen successfully shifted the frame to focus on algorithmic amplification and away from the problematic debate over content moderation and Section 230. This predictably led to a number of calls to regulate the algorithm. Regulate reach, not speech! Rather than regulating speech itself and holding companies liable for the content, the thinking goes, we should hold companies liable for content that is amplified by machine recommendations. Doing this could potentially bring us to hard accountability. Let's have a look, shall we?
Well, the first problem is the pesky First Amendment. Daphne Keller, who wrote a tome on this very topic, put it this way:
Every time a court has looked at an attempt to limit the distribution of particular kinds of speech, they've said, 'This is exactly the same as if we had banned that speech outright. We recognize no distinction.'
Secondly, if we regulated reach, platforms would likely return to a chronological feed. In this case, you would just see posts as they come, instead of seeing what the recommendation engine wants you to see. This sounds fine on paper, but misinformation and harmful content would still be a problem because... people. As Kate Starbird, a professor at the University of Washington said, "In a purely chronological feed, to get stuff to the top, you just put out more crap. It really is going to reward volume." In fact, Facebook already tried this, and it led to more problems for users, and more money for Facebook... whaddya know.
If regulating reach doesn't get us where we want to go, then what's another way of minimizing amplification? One category of solutions focuses on adding friction into the system. Silicon Valley idealizes frictionless experiences. Optimizing for efficiency and removing friction is critical to scale. But inefficiency can be desirable. One prominent approach outlined by Karen Kornbluh and Ellen Goodman is for Facebook to adopt "circuit breakers" for viral content: Facebook would use its data about the velocity of interactions on a post to monitor for virality and then press pause to determine whether the content violates its policies.
The solution I find most intriguing is what Daphne Keller refers to as the "Magic API". This is where third parties can build middleware services for users to interface with Facebook's user-generated content. That means you can pick and choose from a list of curated feeds optimized for different things.

This solution not only addresses Facebook network effects by introducing competition in the form of different feeds but also (potentially) reduces the problem of amplification:
Engagement would be spread across many services, and not centralized on Facebook's platform.
More importantly, middleware services would not necessarily optimize for engaging (re: outrageous) content.
Rather, they would be optimized for different things. I could pick a middleware provider that focused on journalistic content or (more likely) singing competitions and flash mobs.
My interview this month will be with Daphne Keller, so look out for this to learn more about the middleware solution!
☝️ Here's one last idea: it might sound crazy, but maybe Facebook could just do what their researchers told them to do? The Facebook Files revealed that Facebook knows how to tweak its algorithm so that users will see less problematic content. Here are a few things they know:
The 'angry' reaction emoji weighs 5x more than a normal 'like'. If they were given the same weight, it would reduce the spread of misinformation, hate speech, and violent content by up to 5%.
A post reshared 20x in a row is 10x more likely to contain misinformation, hate speech, and violent content than something that hasn't been reshared.
If they increase the weight to the "news ecosystem quality" or NEQ score, people see more quality news.
Three percent of U.S. users account for 37% of known consumption of misinformation on the platform.
In short, Facebook could turn off or limit the reshare function (whether this would violate the First Amendment is disputed), and implement any number of tweaks that would reduce the spread of harmful content, and increase the spread of reliable news — they just aren't doing it.
💡New assumption: scale amplifies the good, the bad, and the ugly of society. Inefficiencies and friction can be good. Addressing the problem that scale creates means breaking network effects and minimizing amplification.
That's all three of the solutions! Unsatisfied yet?
I hope you found this transparency framework helpful — I certainly did! It's easy to forget that transparency is not our ultimate goal — rather, it's a potential stepping-stone on the way to accountability. To move from one to the other, we need to look at the humans and the power dynamics which led to these structures being put in place. We need to require Facebook to account for its own actions and answer to its users' preferences.
I also think it's crucial that we start asking new questions. Instead of wondering how to 'fix' Facebook,' we should ask, 'how do we improve our information ecosystem?'. That question makes room for solutions like taxing targeted advertising, thus freeing up funds to support local news, and the development of alternative systems guided by new assumptions and values.
It's hard to come back from this, but somehow 'more technology' has become justified on its own terms, as a representation of progress. But technology, just like transparency, is only ever a means. It's up to us to define the ends.
Thank you to William Partin for discussing the idea of the transparency feedback loop and its relationship to 'runaway surveillance' with me; to Emmanuel Moss for providing comments on an earlier draft; and to Georgia Iacovou for editing.
Very interesting. Thanks. Essentially the same issues apply to any knowledge ecosystem. Academics rely on citation counts (a horribly crude measure with lots of bugs in it) and recommendations from academic sources. Important ideas may not be noticed - e.g. Mendel's genetics but there must be many other ideas that were ignored but might have benefitted humanity if they had been picked up. Before the web, the news people got would depend largely on the whims of newspaper editors driven probably largely by anticipated profits - a less formal and more transparent equivalent of Facebook and Google's algorithms. How people's attention is controlled is a fascinating and important question which has far wider relevance than the secret algorithms in tech products.
Focusing on one company or a small group of actors will not fix a systemic problem. The internet grew up without a corresponding economic protocol stack adjacent to its 4 layer stack. Aka settlements. These act as incentives and disincentives across and between networks, applications and users.