

AI companies are running out of high-quality data. Here's what happens next.
AI companies are running out of high-quality data. Here's what happens next.
PLUS: I need your help.

Hi, it’s Charley, and this is Untangled, a newsletter about technology and power. Help me get to know you and your Untangled needs:
Last week I published a special issue detailing how we - yes, you! — co-construct training datasets for AI. For those keeping score, there are now six special issues for paid subscribers:
🖼️ The Primer: A 5,000-word synthesis of the themes from my essays. I explain each theme — there are 13 currently — and offer resources and daily actions to make the ideas practical.
🤯 Technically Social: Whereas the Primer focuses on how social systems shape technology, Technically Social is a 3,000-word synthesis of how technology shapes social systems: the materiality of the technology, how it is designed and developed, what it affords, whether it is a tool or arranged in a system, how its effects are ecological.
✔️ The Checklist: Eleven different daily actions — invitations and provocations — you can use in your own lives to make the ideas in Untangled more practical.
📖 AI & Crypto Reading Lists: I curated and synthesized my favorite news articles, academic papers, and books that explain how AI and crypto are entangled in social systems like gender, race, and power.
This week, the biggest story in tech is about how OpenAI, Google, and Meta “ignored corporate policies, altered their own rules and discussed skirting copyright law as they sought online information to train their newest artificial intelligence systems.” They found, for example, that OpenAI built a tool, Whisper, to transcribe audio from YouTube Videos, which is likely a violation of Google’s terms of service. Not great.
But the main tidbit to catch my eye? To address the impending shortage of high-quality data, the reporters found that OpenAI plans to use synthetic data (i.e. data generated by their models) as future training data. OpenAI CEO Sam Altman is publicly confident, saying “As long as you can get over the synthetic data event horizon, where the model is smart enough to make good synthetic data, everything will be fine.”
Everything won’t be fine. Last August I explained the consequences of this very approach in “The Doom Loop of Synthetic Data.” I’ve decided to free it from the paywall and reshare it to help you untangle the news, and make sense of this impending future.
The Doom Loop of Synthetic Data

Sometimes it feels like I’m playing a game of ‘narrative whac-a-mole.’ A silly AI narrative pops up — e.g. it has emergent properties! it hallucinates! — and then I (and many others) give it a whack. And this happens over and over.
The latest narrative in AI? Continuous improvement: sure, these systems might produce unreliable or harmful results now, but they’ll continue to get better. But what if that narrative isn’t true? What if we run out of high-quality data to train AI systems? That might sound like an absurd hypothetical — but a recent paper actually argues otherwise, predicting that we’ll run into a “bottleneck for training data” between 2030 and 2050.
The improvement to large language models we’ve seen over the last few years comes from training them on lots of data. In particular, high-quality data — from books, scientific papers, public code repositories like GitHub, and other high-quality datasets like Wikipedia. The problem? It’s possible that ChatGPT-4 is trained on trillions of words. As Ross Anderson of The Atlantic writes, “Ten trillion words is enough to encompass all of humanity’s digitized books, all of our digitized scientific papers, and much of the blogosphere.” So where will the next ten trillion words come from, how will they be digitized and stored, and who will have access to it?
In “Will we run out of data?” Pablo Villalobos et al. use a number of assumptions about the growth of cultural production, internet penetration rates, compute availability, and forecast that high-quality language data will be exhausted by 2027. The paper concludes, “If our assumptions are correct, data will become the main bottleneck for scaling ML models, and we might see a slowdown in AI progress as a result.” Even if their assumptions aren’t correct, it still stands to reason that it’s only a matter of time. ChatGPT is trained on data scraped from the web. As a larger percentage of the web is made up of ChatGPT outputs, the more future models will be trained on data produced by prior models — it’s like a snake eating its own tail.
Imagine a future where there isn’t enough high-quality data — what might companies building these systems do? Villalobos speculates on different ways we might be encouraged to record our own speech and share it with companies. For example, he imagines a future where we wear dongles around our necks! As ridiculous as that sounds, we already passively record data about ourselves for the benefit of profit-making companies just by having phones, browsing the web, and using IoT devices. So it’s not too hard to imagine a situation where companies market new technologies to us under the guise of wellness or productivity (or something), in order to capture even more data.
Technologists will likely find new ways to increase storage and compute availability, but it’s the high-quality data itself that is the bottleneck. We can’t just turn on the cultural production faucet and rapidly produce more books and scientific papers — though, I wouldn’t be surprised to see tech CEOs start funding these efforts as a bank-shot attempt to meet their data needs. Nor do I expect tech companies to just say ‘ah, well, we gave it our best shot, time to give up on this whole AI pipe dream.’ So the only other option is to use data of ever-dwindling quality.
The first stop on the search for lower-quality data will be user-generated content. Your texts, posts, Tweets, Stories, and Notes will be what train our future AI overlords. Already, OpenAI wants you to upload your own data and files to help train ChatGPT.
But Villalobos actually predicts that low-level language data will be exhausted between 2030 and 2050. If low-quality data isn’t enough, what happens next?
Companies will start using synthetic data — the outputs generated by the models themselves — as subsequent training data. This might already be happening: a former Google AI engineer left for OpenAI after alleging that Google trained Bard, its chatbot, using data generated by ChatGPT. This is a big problem — consider the difference between training a model on scientific articles, and training a model on probabilistic outputs, which are often inaccurate. Writing about image generation, Ted Chiang likens this process to “the digital equivalent of repeatedly making photocopies of photocopies in the old days. The image quality only gets worse.” This, of course, hinges on the assumption that the quality of the data generated is worse than the training data.
Enter the idea of feedback loops from complex systems. In systems thinking, feedback refers to “any reciprocal flow of influence.” according to Peter Senge, author of The Fifth Discipline. In other words, Senge writes, “Every influence is both cause and effect. Nothing is ever influenced in just one direction.” In its current state, ChatGPT has been trained on more high-quality data than low-quality data. But over time that proportion is going to flip. This is the beginning of our loop:
An increase in low-quality data relative to high-quality data >>
Leads to a relative increase in the use of lower-quality data to train AI models >>
Leads to a relative increase in lower-quality data outputs >>
This is a reinforcing feedback loop that looks something like this:
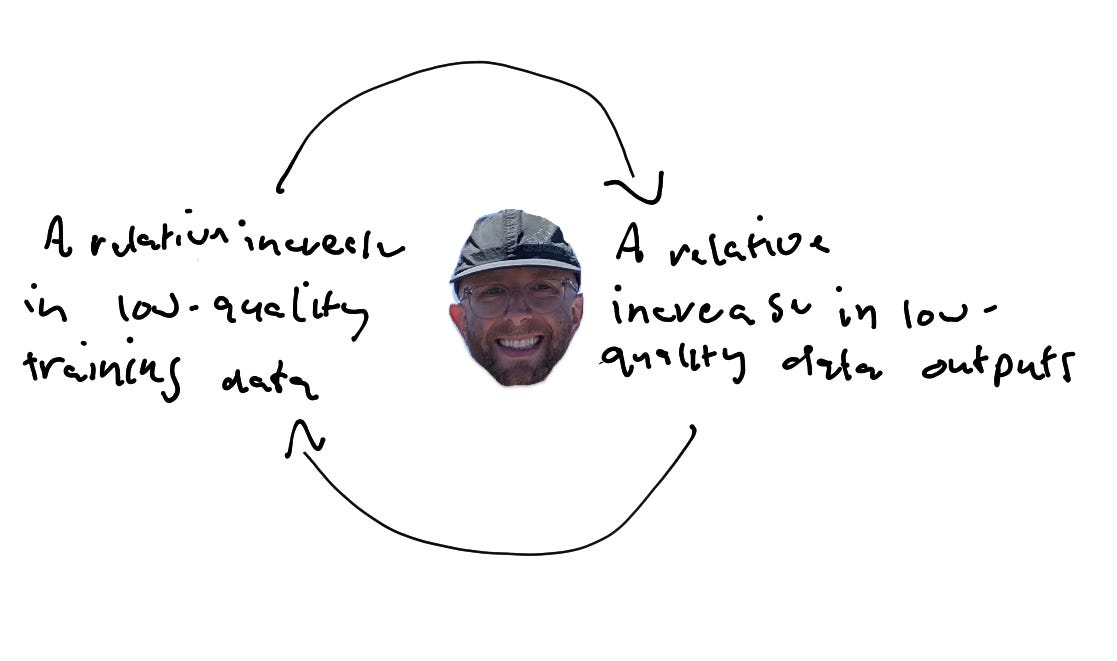
This kind of feedback loop is an engine of growth — it either amplifies something positive or accelerates its decline. In this case, it is accelerating decline. As Senge writes,
“Whatever movement occurs is amplified, producing more movement in the same direction. A small action snowballs, with more and more and still more, resembling compounding interest. Some reinforcing processes are ‘vicious cycles’ in which things start off badly and grow worse.”
AI researchers are already demonstrating this process. Researchers at the University of Oxford, the University of Cambridge, the University of Toronto, and Imperial College London trained a model on synthetic data and found that it causes “irreversible defects in the resulting models.” They go on to basically describe the feedback loop I depicted above, writing:
“We discover that learning from data produced by other models causes model collapse – a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time.”
Model collapse sounds … bad. One way to avoid all of this would be to prohibit the use of synthetic data in training sets. At the very least, we should monitor whether these systems start to incorporate their outputs as training data. Ted Chiang offered this idea, writing “If the output of ChatGPT isn’t good enough for GPT-4, we might take that as an indicator that it’s not good enough for us, either.”
It’s hard to know how this plays out because there is no clear ‘ending’ to a narrative of continuous improvement. If we assume that AI can indeed improve forever, and prioritize pursuing this, I can foresee two paths, which could easily happen in tandem: one is where the need for high-quality training data becomes urgent, and therefore expands and intensifies the agenda of personal data collection set by technology companies. The other path will see greater and greater amounts of synthetic data used to train models, thus perniciously morphing ‘continuous improvement’ into ‘continuous degradation’, and creating a context where we persistently justify the use of AI, while suffering the consequences of its harmful outputs.
Personally I'd be quite suspicious that uploading documents to ChatGPT will really provide them with the sheer quantity of data that they need. I'd also be suspicious because Google produces Chromebooks and Microsoft/OpenAI produces Windows (most prevalent/common consumer, education, and commercial OSes) and "accidentally" help themselves to training data, possibly under the guise of "scanning for malware". They're closed source, too, so it's not like anyone would have the ability to audit.
I fully expect that within the decade there will be some huge breach at one or both of these companies because a vault of "training data" will have been exposed, along with PDFs of everyone's tax returns. I also fully expect nothing to come of this unless it were proven that the secure files of a company of sufficient weight (like the US government itself) were harmed by such an event.
The 'narrative whack-a-mole' really resonates - I work in the digital wellbeing space (how technology use in all its forms shapes our psychology) and I feel I've been playing this game for years and years now.
In talking about data quality, you've gotten me thinking about the changes in quality of human output (and communication) over the ages - for the worse. If the current and future data sets are going to be based on what we output through our most-used communication channels - social media and texting - we're in a lot of trouble.